Collecting Feedback and Iterating
Learn to collect user feedback and implement data-driven product improvements.
Product testing is a powerful way to improve what you build based on actual user behavior. A/B testing compares different versions of a feature to see which one performs better according to specific metrics like conversion rates or engagement. This approach removes guesswork from product decisions by showing exactly how users respond to different options. Regular testing cycles help teams catch problems early, validate new ideas before full implementation, and continuously refine the product experience. The data gathered through testing creates a foundation for evidence-based improvements rather than decisions based on opinions or assumptions. Products that evolve through systematic testing tend to better meet user needs while achieving business goals, making experimentation an essential practice for effective product management.
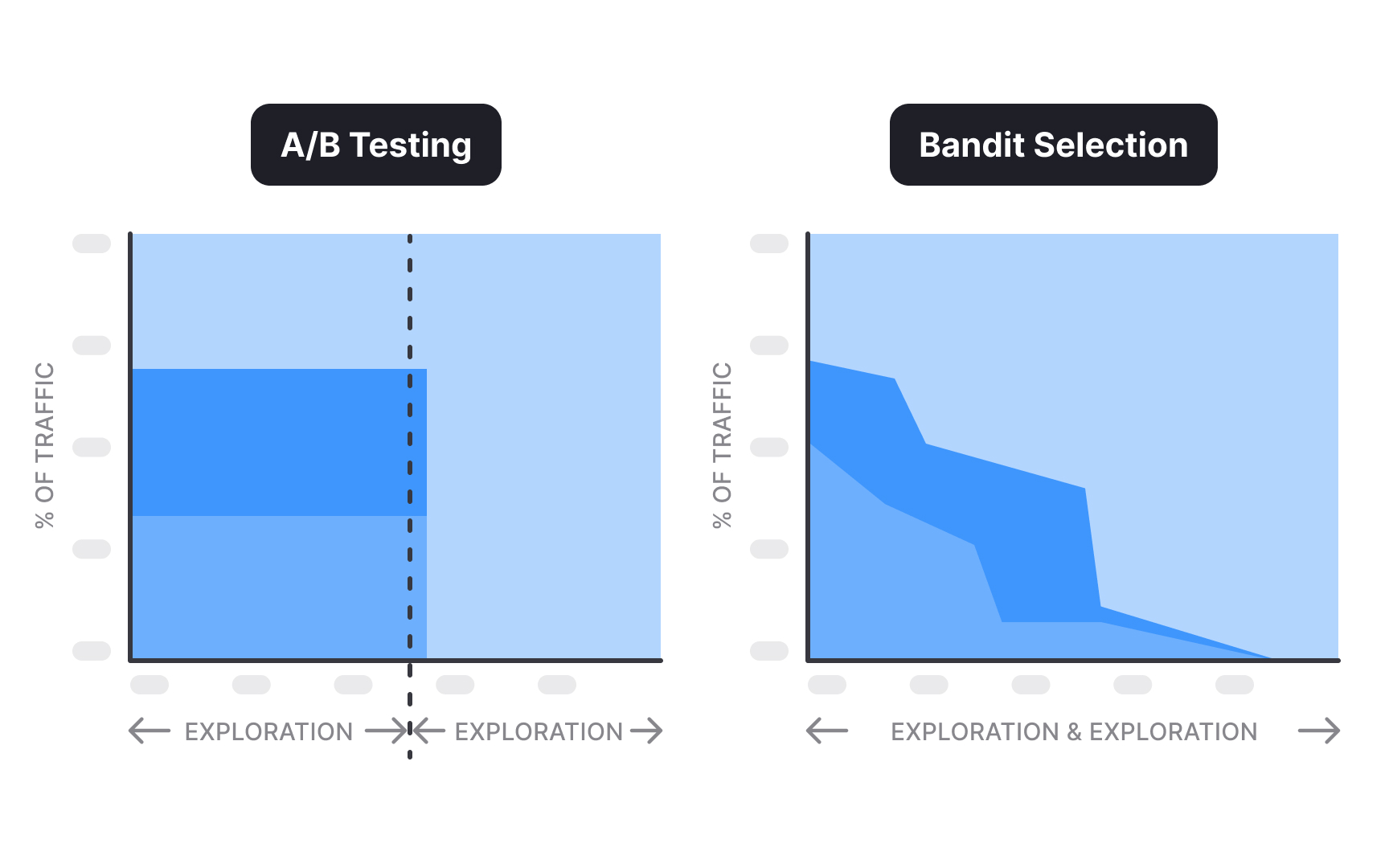
Common A/B test types include:
- Standard A/B tests: Split traffic evenly between two variants to determine which performs better. This is the simplest form of experimentation.
- Feature tests: Evaluate new functionalities before full development. This pre-launch testing validates hypotheses about user interactions with potential features.
- Live tests: Compare variations of an existing product that's already available to users. These tests optimize elements of your product to improve conversion, engagement, or retention.
- Multi-armed bandit (MAB) tests: Use machine learning to dynamically adjust traffic distribution, automatically directing more users toward better-performing variants during the test. This balances learning with immediate optimization.
- Multivariate tests: Examine multiple variables simultaneously to understand how different elements interact. These require larger sample sizes but provide more nuanced insights.
When choosing a test type, consider:
- Your available user traffic
- The complexity of what you're testing
- How quickly you need results
- The importance of statistical certainty[1]
Pro Tip: For critical product changes, standard A/B tests with fixed traffic allocation often provide clearer statistical confidence than dynamic allocation methods.
Product features are the building blocks of your application, and testing them properly ensures you're delivering value to users. Testing methods vary and depend on the feature's complexity and importance.
When testing product features, focus on these key elements:
- User-facing elements: Test buttons, forms, user flows, and interface components that directly impact how users interact with your product.
- Critical functionality: Prioritize testing features that are core to your product's value proposition or that users depend on regularly.
- Potential high-impact changes: Features that could significantly improve
conversion rates , engagement, orretention deserve thorough testing. - Problem areas: If analytics show that users are struggling with specific features, these should be prioritized for experimentation and improvement. To support decision-making, consider scoring each problem area by its severity.
For effective feature testing:
- Define what success looks like for each feature through clear metrics like adoption rate, completion time, or error rate.
- Start with controlled experiments where one variable changes at a time to clearly identify what impacts user behavior.
- Consider context and timing when launching tests. Feature usage often varies based on user segments, time of day, or device type.
- Follow up with qualitative research to understand the "why" behind test results. A feature might statistically "win" a test but create confusion for users.[2]
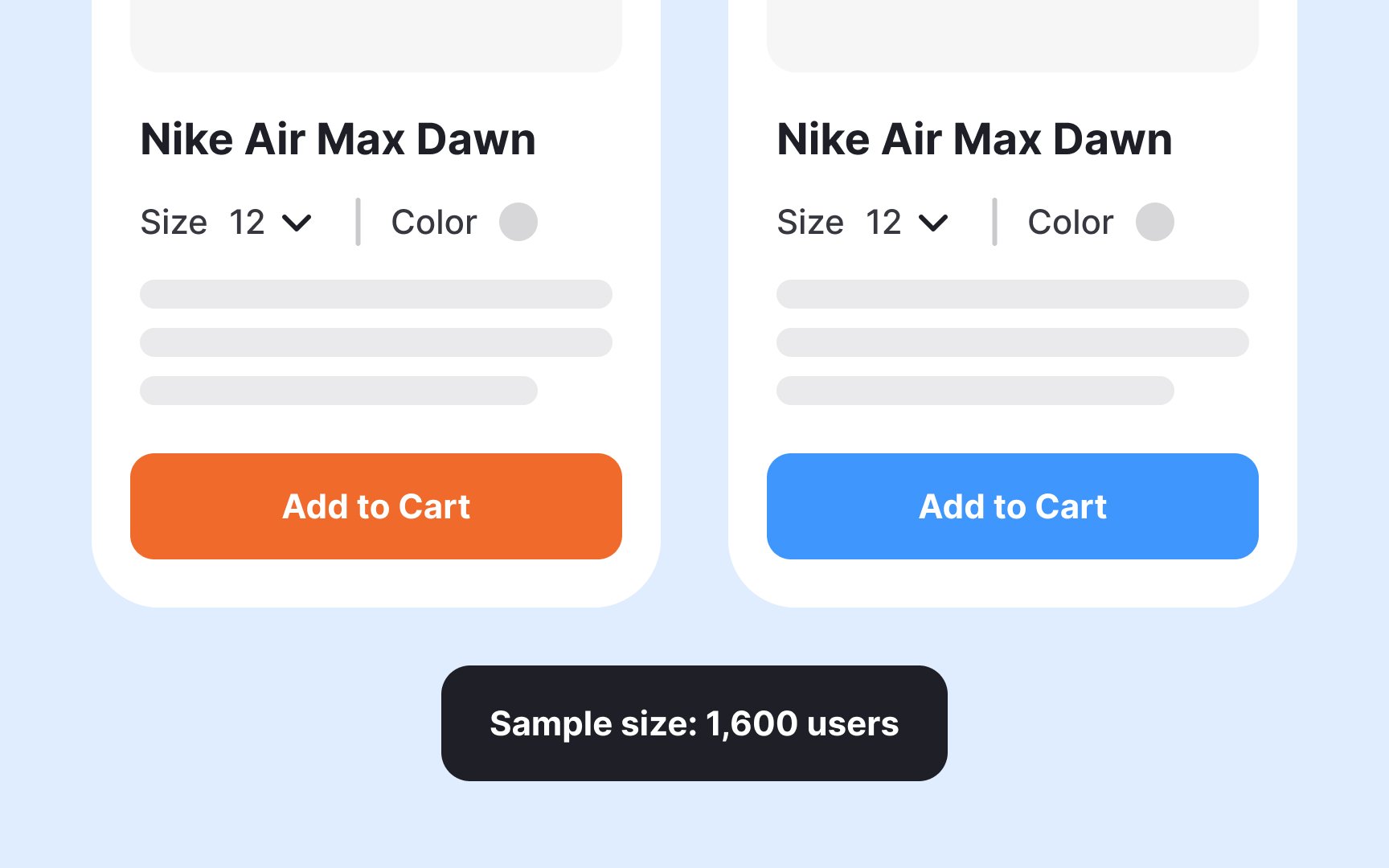
Sample size defines the number of users needed in each test variation and directly impacts the reliability of your
Four key factors determine your required sample size:
- Expected effect size: The magnitude of the difference between variations. Smaller differences need larger samples because they're harder to distinguish from random fluctuations.
- Baseline conversion rate: Your current performance level. Lower baseline rates require larger samples to detect meaningful changes.
- Statistical confidence level: Typically 95%, indicating you're 95% confident your results aren't due to chance.
- Statistical power: Usually 80%, representing the probability of detecting a true effect when it exists.
When planning your sample size:
- Use a sample size calculator as a starting point
- Assess if your traffic volume can support the recommended sample size within a reasonable timeframe
- Define what minimum improvement justifies the resources required for testing
- Consider whether seasonal patterns might affect your results if the test duration is too short
The right sample size balances statistical validity with practical testing constraints. Too small a sample risks unreliable conclusions, while unnecessarily large samples waste time and resources. If your organization has analysts or data scientists, consider involving them early. They can help you determine the appropriate sample size and estimate how long the test needs to run.
Pro Tip: Most A/B testing tools include sample size calculators that help determine how much traffic you need based on your specific parameters.
While
Key elements of multivariate testing include:
- Variables: The specific elements you're testing (button color, headline text, image placement)
- Variants: Different versions of each variable (blue/green/red
buttons ) - Combinations: All possible arrangements of your variables and variants
Setting up a proper multivariate test requires:
- Identify independent variables that might impact user behavior
- Create variations for each variable
- Determine test combinations. These grow exponentially (3 variables with 3 variants each create 27 combinations).
- Allocate sufficient traffic to each combination - multivariate tests require substantially more traffic than A/B tests.
- Define clear success metrics that will determine which combination performs best.
Multivariate testing is valuable when you need to understand how different elements interact, rather than testing isolated changes. However, because it involves multiple variants and combinations, it typically takes longer to see meaningful results. You'll also need to ensure you have enough traffic to support the number of variants included in the test.
Even carefully designed tests can produce misleading results when biases creep in. Testing bias occurs when factors other than your test variables influence the outcome, compromising the validity of your experiments.
Common testing biases to watch for include:
- Selection bias: When your test subjects aren't representative of your actual user base. For example, testing only with power users skews results toward expert behavior patterns.
- Timing bias: Seasonal factors or time-based events can affect user behavior. Testing during holidays or special events may produce results that don't represent normal conditions.
- Novelty effect: Users often respond differently to new features simply because they're new, not because they're better. Initial excitement can inflate performance metrics temporarily.
- Order bias: The sequence in which variants are presented can influence results, especially in usability testing, where learning affects subsequent
interactions .
To minimize these biases:
- Use proper randomization when assigning users to test groups to ensure representative samples.
- Run tests for adequate durations to account for day-of-week variations and novelty effects.
- Establish control groups that receive no changes to benchmark against external factors affecting all users.
- Segment your analysis to verify consistent performance across different user types and conditions.
Eliminating all bias is impossible, but recognizing and accounting for potential sources of bias leads to more trustworthy test results and better product decisions.[3]
Product improvement isn't a one-time event but an ongoing process. Continuous testing creates a regular system of experiments that drives product evolution based on real user data.
Instead of treating testing as a separate activity, continuous testing becomes part of your normal development cycle. This ensures decisions are consistently data-driven and your product improves step by step.
Key elements of effective continuous testing include:
- Test prioritization: Focus on experiments that address important areas of your product based on user data, business goals, and strategic priorities.
- Testing calendar: Maintain a schedule of planned experiments to ensure regular testing without overwhelming your team or users.
- Documentation process: Record your hypotheses, test designs, and results where all team members can access them to build shared knowledge.
- Learning loops: Create ways to apply insights from one test to inform future experiments, building a cycle of ongoing improvement.
To implement continuous testing, start small with one clear area of your product, set measurable success metrics, and gradually expand your testing program as you gain experience.
The most successful product teams make testing a habit rather than an occasional activity, constantly checking assumptions and refining the user experience based on actual behavior.
Pro Tip: Create a "testing backlog" similar to a product backlog, where potential experiments are prioritized based on expected impact and implementation effort.
Gathering test data is only valuable when it leads to real product improvements. Turning test results into actual changes requires a clear process that connects your experiments with development work.
Here's how to effectively use testing feedback:
- Look deeper at results: Go beyond basic numbers to understand what users are really doing. A winning test variant should represent genuine user value, not just statistical significance.
- Choose which changes to make: Not every successful test should be implemented right away. Consider how each change fits with your overall product plans and priorities.
- Make specific action plans: For test variants you decide to implement, create clear tasks that specify exactly what needs to change and who will handle it.
- Keep watching after changes: Once you've made changes based on your tests, continue measuring the same metrics to make sure the improvements work in the real product.
The best product teams create a quick cycle where test insights directly drive product updates. This approach helps your product evolve rapidly based on actual user behavior rather than assumptions.
Remember that tests showing no improvement are still valuable, as they save you from making changes that wouldn't help users.
Pro Tip: After each test, hold a brief meeting where the team reviews results and agrees on next steps to ensure everyone understands the data-driven decisions.
Tracking product evolution through testing gives evidence of progress and highlights areas needing attention. Effective measurement captures the cumulative impact of your improvement efforts, not just individual test results.
Important metrics to monitor include:
- Baseline metrics: Establish starting points for critical indicators like
conversion rates , engagement, andretention . - Improvement velocity: Track how quickly you implement and validate enhancements, showing your process efficiency.
- Cumulative gains: Calculate the combined effect of multiple small improvements on key business metrics.
- User satisfaction trends: Monitor how sentiment evolves alongside product changes through surveys or NPS.
- Regression indicators: Watch for decreasing metrics that might signal unintended consequences of changes.
For effective measurement:
- Create a dashboard showing key metrics over meaningful time periods
- Annotate product changes directly on trend lines to connect improvements with metric shifts.
- Review long-term trends regularly to identify sustained patterns.
- Share improvement metrics widely to build confidence in your approach.
Remember that meaningful product evolution emerges gradually. Individual tests may show immediate results, but the real impact comes through consistent application over time.
Creating lasting product improvement requires more than just tools and processes. It demands a culture that embraces experimentation and values evidence over opinions. Building this culture transforms testing from an occasional activity into a fundamental part of how your team works.
Key elements of a strong experimentation culture include:
- Leadership support: Senior stakeholders and team leaders must visibly champion experimentation, allocate resources for testing, and use data in their own decision-making.
- Psychological safety: Team members need to feel safe proposing experiments without fear of blame if results don't match expectations. Failed tests should be viewed as valuable learning opportunities.
- Shared vocabulary: Establish common terms and concepts around experimentation so everyone communicates clearly about tests, results, and implications.
- Celebration of learning: Recognize and reward valuable insights gained through testing, not just "successful" outcomes that confirm existing beliefs.
- Democratized testing: Make experimentation accessible to everyone, not just data scientists or product managers, by providing simple tools and basic training.
When building this culture, start with small wins that demonstrate the value of experimentation. Share success stories widely and create visible artifacts, like
Remember that shifting culture takes time. Consistent messaging and behaviors from leaders will gradually influence how the entire team approaches product development.
Pro Tip: Include "What did we learn?" as a standard question in team meetings to emphasize that gaining insights is as important as shipping features.
References
- The Guide to A/B Testing in Product Management | Thoughts about Product Adoption, User Onboarding and Good UX | Userpilot Blog
- The Guide to A/B Testing in Product Management | Thoughts about Product Adoption, User Onboarding and Good UX | Userpilot Blog
Topics
From Course

Share
















Similar lessons

Analytics Strategy & Planning
Data Collection & Tracking
