Understanding AI Errors
Recognize different types of AI errors and their impact on user experience.
AI systems make mistakes differently than traditional software. While a calculator gives wrong answers only when broken, AI can produce incorrect results even when working perfectly. This happens because AI operates on probability, making educated guesses based on patterns in data.
These errors take many forms. A photo app might label your cat as a dog. A music service might recommend heavy metal to a jazz lover. A navigation system might suggest a route through a flooded road. Each represents a different type of failure with unique causes and solutions. What makes AI errors particularly complex is that users and systems often disagree about what counts as an error. When a recommendation system suggests something unexpected, is it discovering your hidden interests or simply getting it wrong? The answer depends on context, user expectations, and how well the system understands your current situation.
Understanding these error types helps product teams build better experiences. By recognizing patterns in how AI fails, designers can create appropriate safeguards, set realistic expectations, and provide users with meaningful ways to recover when things go wrong.
Traditional software follows clear rules. A calculator processes the same equation the same way every time. When you type 2+2, you always get 4. When something goes wrong, you can trace the exact cause and fix it so the
- Errors happen when AI produces unexpected or inaccurate results. Think of a recipe app suggesting desserts when you search for salads. Users can usually work around these with some extra effort. The system works but gives wrong answers.
- Failures are more serious. They occur when AI faces inherent limitations or stalled processes. Imagine a translation app that simply can't process a rare dialect. It's not broken. It's hitting a fundamental boundary. Failures leave users stuck, unable to complete their task through the AI.
- Disruptions derail users entirely. A smart speaker that randomly announces weather updates during your meditation session doesn't just fail at one task. It actively interferes with what you're trying to do. The AI interrupts your primary activity.
Teams must identify which category they're dealing with to respond appropriately.
Alignment
Imagine opening a recipe app at 6 AM to plan dinner. The app suggests breakfast recipes because it assumes morning equals breakfast time. For most users, this makes sense. But if you work night shifts or plan meals ahead, this assumption fails. The AI lacks the broader context of your daily routine.
These misunderstandings multiply across cultures. A music app might play upbeat party songs during a religious fasting period. A fitness tracker might push intense workout notifications when you're sick. The AI correctly identifies patterns but misses important context about your current state.
The challenge is that AI systems see patterns, not purposes. They process data without understanding the meaning. A spike in restaurant searches might mean you're hungry, planning a birthday dinner, or writing a food blog. The AI guesses based on statistics, not the situation. Each recommendation follows logical data patterns but can feel completely wrong based on your actual needs.
Every
Consider a plant identification app trained on common garden plants. Show it a rare orchid from the Amazon, and it fails. This isn't a malfunction. The app correctly recognizes that this plant falls outside its knowledge. It's like asking a French translator to handle Mandarin. The limitation is built into the system's design.
Users often expect AI to handle anything within its general domain. A weather app should know all the weather everywhere. A translation tool should handle every dialect. But AI systems have specific training that creates natural boundaries. They excel within their focus area but fail at the edges.
Clear communication about these limits builds trust. Instead of vague
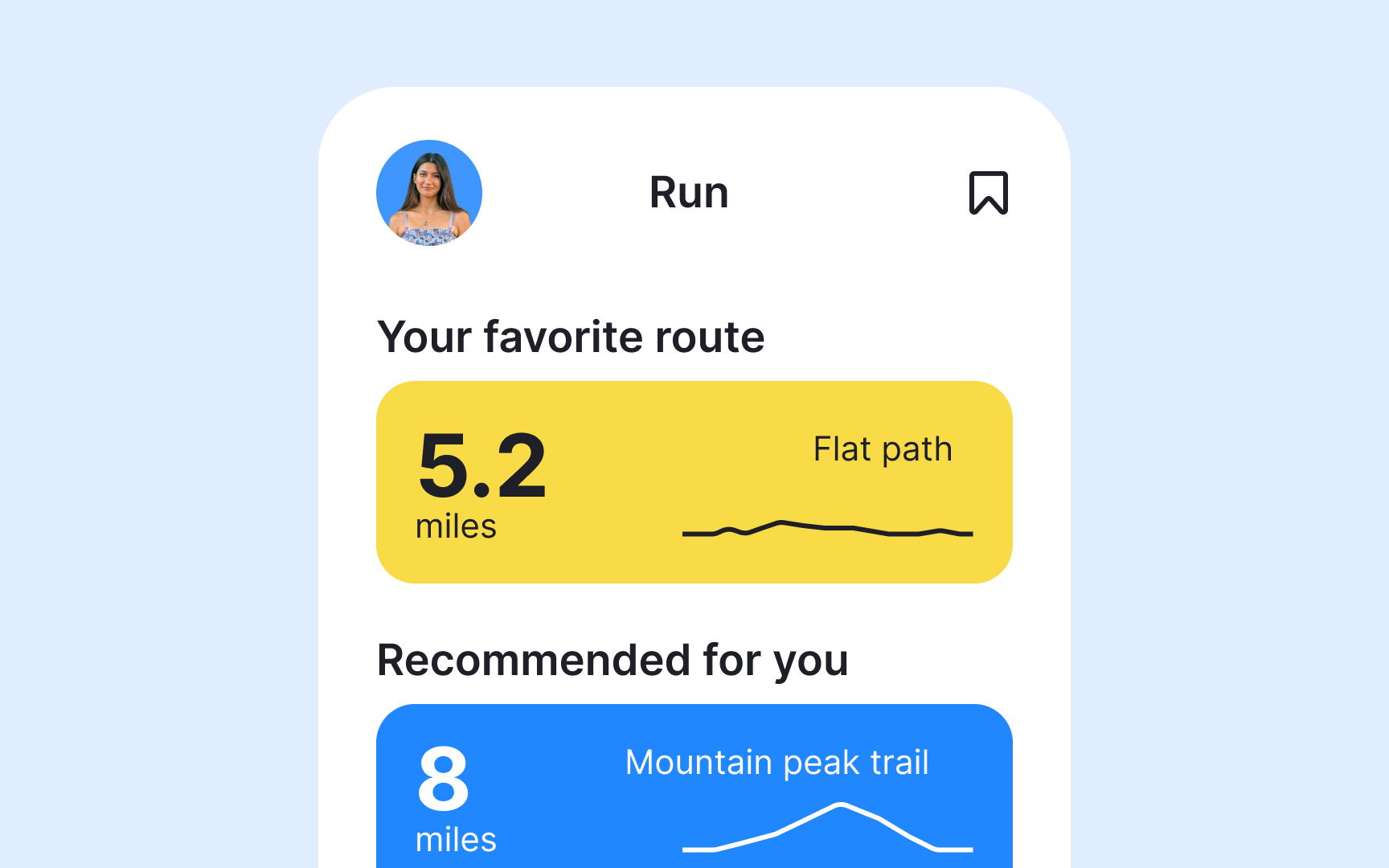
- A true positive happens when RUN suggests a trail you love and choose to run. The AI correctly predicted what you'd want.
- A true negative occurs when RUN avoids suggesting steep trails after you've indicated you dislike inclines. It correctly identified what to exclude.
- False positives frustrate users with irrelevant suggestions. RUN might recommend a mountain trail to someone who only runs on flat paths. The AI wrongly thought this would appeal to you.
- False negatives represent missed opportunities. RUN might skip suggesting a perfect waterfront trail because it misunderstood your preferences.
Not all errors carry equal weight. A false positive in RUN wastes a few seconds. A false negative in a medical AI could miss critical symptoms. A false positive in allergy detection means avoiding safe foods. A false negative could trigger dangerous reactions. Teams must consider these outcome types when optimizing their systems. The same technical error creates vastly different human consequences.
Some "errors" actually benefit users during creative tasks. A writing assistant that suggests an unexpected metaphor might spark better ideas than what users originally intended. These useful inaccuracies help with ideation and expand creative options.
Minor errors slow progress without causing real harm. When a
But errors can escalate to serious harm. A financial AI giving wrong tax advice could trigger audits. A medical AI missing allergies could risk lives. These situations demand conservative design and human oversight.
The most severe errors involve policy violations. Hate speech, dangerous content, misinformation, or child sexual abuse material (CSAM) require immediate intervention. These aren't just inconveniences but potential catastrophes. Design teams must map where each feature falls on this spectrum and build appropriate safeguards. Creative tools can embrace useful inaccuracies. Critical systems need conservative designs that prevent harmful errors.
Context determines whether an
Research helps teams gauge error risk systematically. Users with expertise tolerate
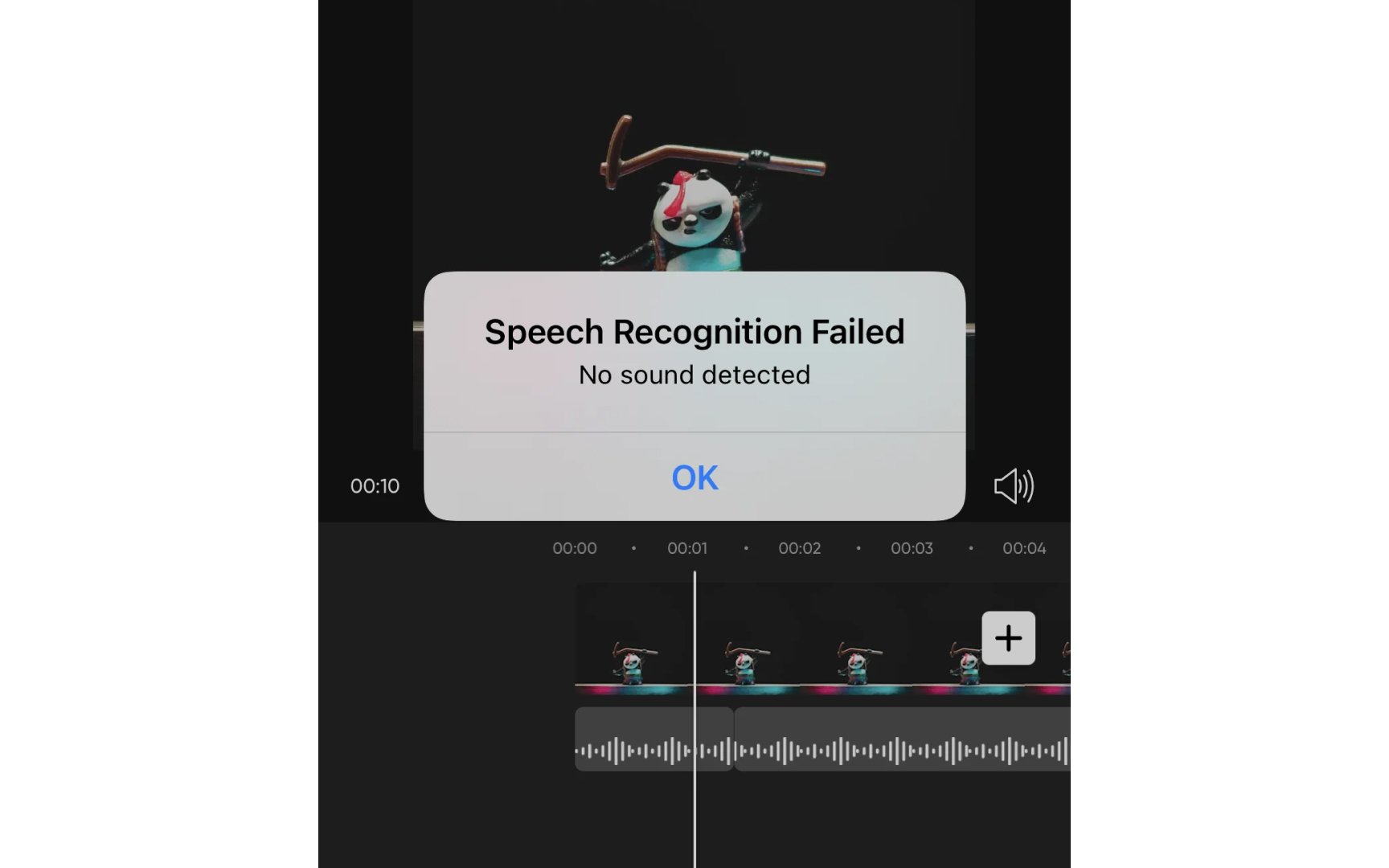
Consider training data problems first. A voice assistant trained mostly on American English fails consistently for British users. Every British person experiences identical recognition failures. These aren't random bugs but systematic blind spots.
Mislabeled training data causes especially confusing mistakes. If training data mixed up muffins and cupcakes, the AI now confidently misidentifies every muffin. Users see obvious errors and wonder how advanced AI fails at simple tasks. They don't know the AI learned these mistakes from its training.
Input errors frustrate differently. Users expect AI to understand typos and context.
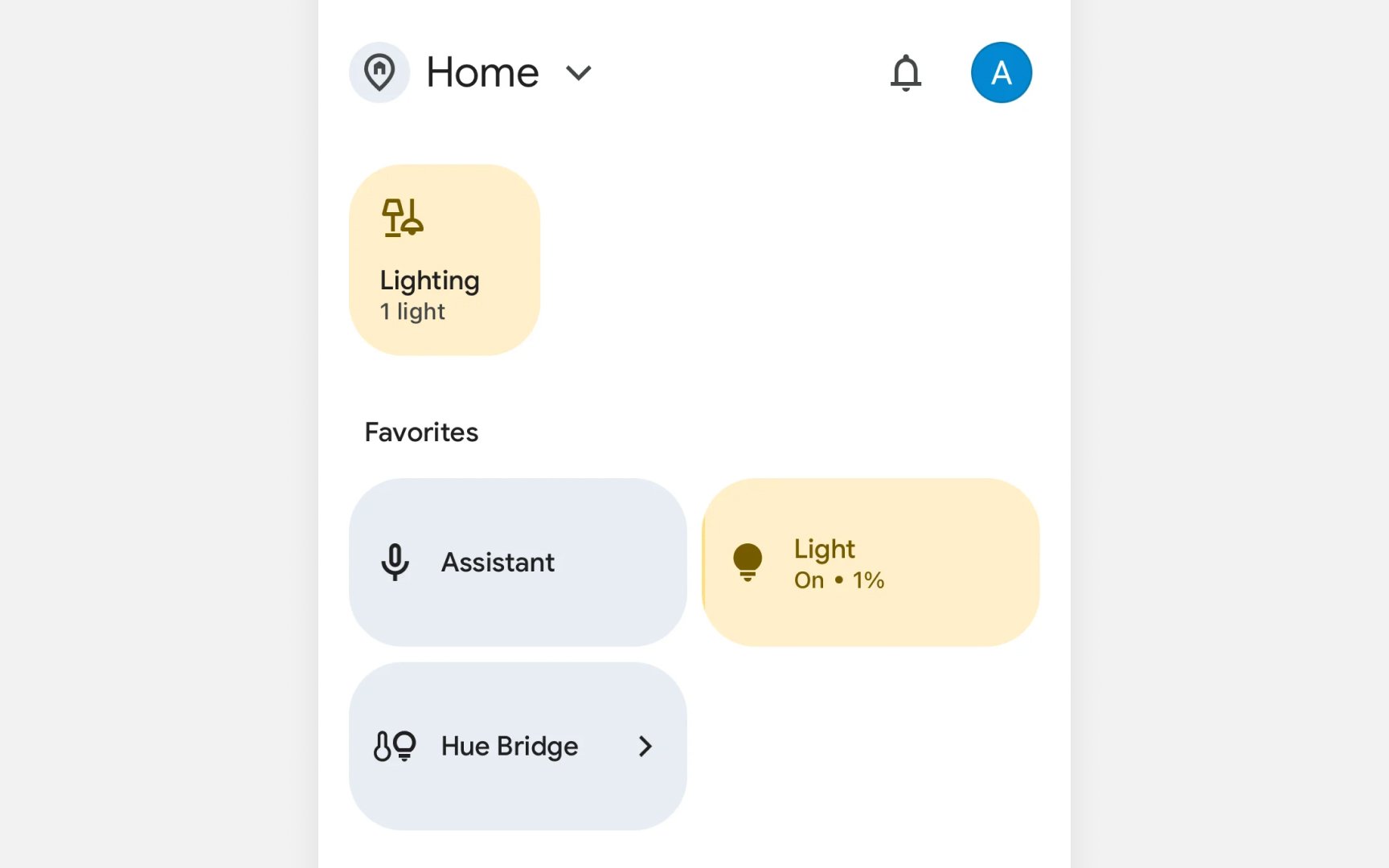
Modern homes often have multiple
Voice commands trigger multiple responses. Say "play music" and your phone, smart speaker, and TV might all respond. Each device correctly heard you, but their overlapping responses create noise instead of help. Users can't process three different audio streams or figure out which device to address next.
These conflicts need designed solutions, not technical fixes. Users should control which system takes priority in different situations. Clear interfaces must show when systems disagree and explain why. Without this coordination, adding more AI to daily life creates confusion instead of convenience.
References
- People don’t trust AI – here’s how we can change that | The Conversation
Top contributors


Topics
From Course

Images provided by

Share















