Learning from Your Launches
Turn every product launch into valuable insights that drive your next strategic decisions.
Post-launch analysis separates successful product teams from those who simply ship features. This critical phase determines whether your experiments validated core hypotheses and reveals unexpected user behaviors that shape future iterations.
Effective learning from launches requires structured documentation, collaborative analysis, and honest evaluation of what worked versus what surprised you. Teams that master this process build a compounding advantage by turning every launch into valuable intelligence about their users and market.
The difference between shipping and learning defines whether products evolve purposefully or drift aimlessly. Through systematic experiment analysis and team retrospectives, product managers extract maximum value from every launch. This creates a repository of validated learnings that inform strategic decisions and prevent repeated mistakes.
Many teams celebrate shipping features but miss the critical question: did you actually test what you set out to learn? The gap between what teams think they tested and what they actually tested can be surprisingly wide. Your experiment design determines whether you generate valid learning or just collect meaningless data. Testing entire ideas instead of specific assumptions creates muddy results that leave you guessing about what worked and what didn't. This wastes precious time and resources while giving you false confidence about your direction. The most valuable experiments isolate your riskiest assumption and test it directly. Before running any test, clearly define your "leap of faith" assumption. What single belief, if proven wrong, would force you to reconsider your entire approach? Design your experiment to test only that assumption, not the whole solution. This clarity transforms vague feedback into actionable insights that guide your next steps.[1]
Good
Effective experiment docs start with a clear hypothesis written before you run the test. State exactly what you expect to happen and why. Include your success criteria upfront. What specific metrics or behaviors would convince you the hypothesis is true? What results would prove it false? This pre-commitment prevents you from retrofitting explanations to match whatever happens.
Your documentation should capture the experiment setup, participant criteria, and exact conditions. Include screenshots, prototypes, or test materials so others can understand exactly what users experienced. Document both quantitative metrics and qualitative observations. Most importantly, record your conclusions and next steps while the insights are fresh. These documents become your team's learning library, turning individual experiments into organizational knowledge.
Not all metrics deserve your attention. Teams often drown in data while missing the signals that actually show progress toward their goals. Vanity metrics make you feel good but don’t support decisions. High page views, for example, say little about whether users find value. Actionable metrics, in contrast, link directly to user behavior and business outcomes, helping you see cause-and-effect relationships that guide choices.
To keep decision-making clear, focus on the essentials. Tie one or two success metrics directly to your hypothesis, and add a guardrail metric to catch unintended consequences. For instance, if you are testing whether users will pay for a feature, track conversion rates as your success metric and churn as your guardrail. Leave everything else aside unless you want to explore new hypotheses. This discipline ensures metrics drive decisions instead of distracting from them.
The most valuable insights often come from unexpected user behaviors. These surprises reveal the gap between your assumptions and reality, offering rich opportunities for innovation. Users rarely behave exactly as we predict. They find creative workarounds, use features in unintended ways, or ignore elements we thought were essential. These behaviors aren't failures. They're windows into user needs you hadn't considered. When Twitter users spontaneously started typing "@username" to talk to each other, they revealed a need for conversations that Twitter hadn't designed for. Instead of stopping this behavior, Twitter built it into a core feature. Combining quantitative data with user feedback helps you understand not just what happened, but why.
Create space in your analysis for surprises. Look for patterns in unexpected behaviors. When users consistently misuse a feature, they're often trying to solve a different problem than you imagined. Talk to these users. Their creative adaptations often point toward better solutions than your original design. Remember that confused users aren't at fault. They're showing you where your mental model doesn't match theirs.[2]
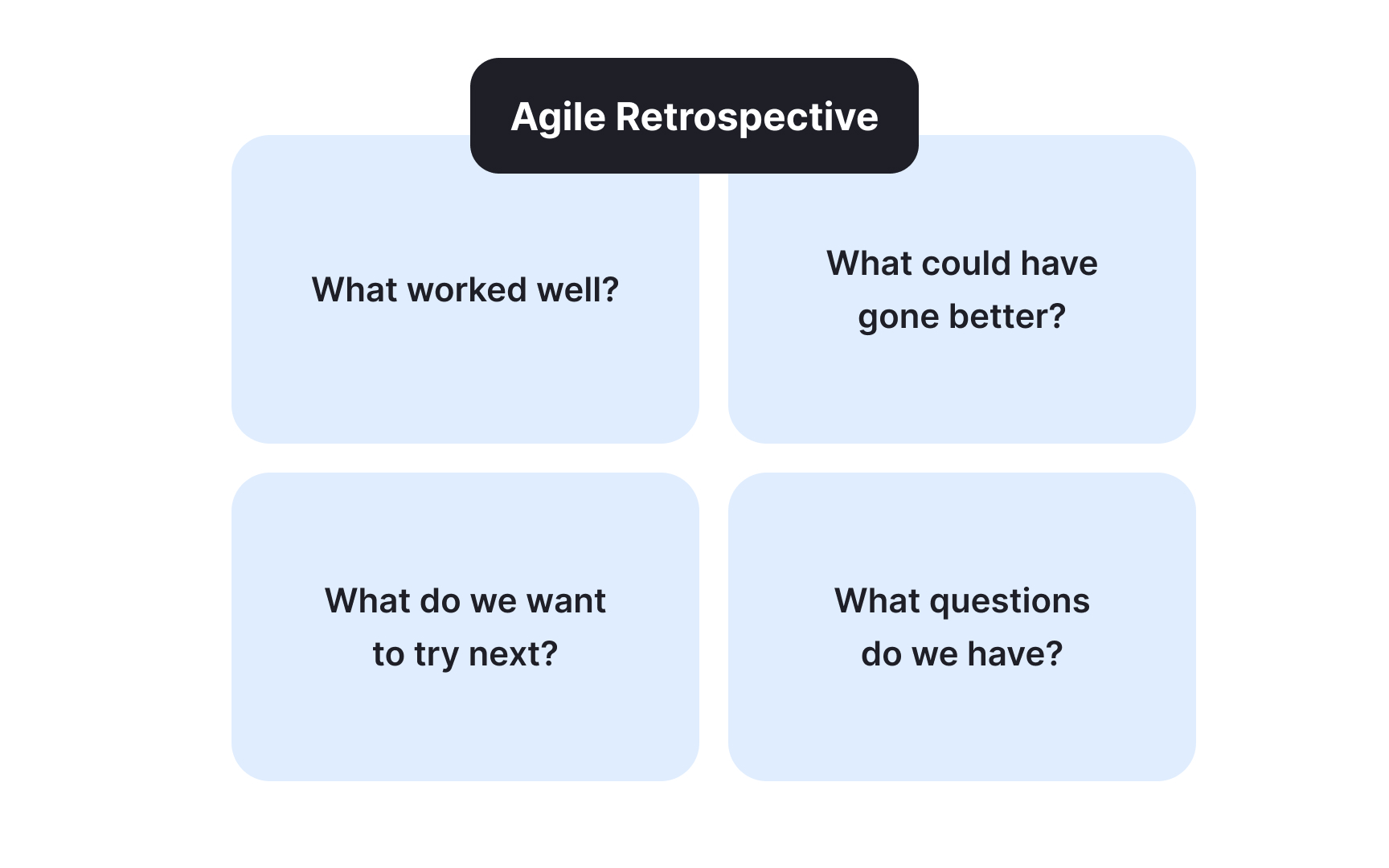
Post-launch retrospectives determine whether your experiments generate lasting insights or forgotten lessons. The quality of these sessions directly impacts your team's ability to improve.
Structure your learning sessions to maximize honest discussion and creative problem-solving. Start by reviewing the original hypothesis and success criteria. Present the data without interpretation first, allowing team members to form their own conclusions. Create psychological safety by celebrating learning, not just positive results. Failed experiments that generate clear insights are more valuable than ambiguous successes.
Ask provocative questions: "Who's surprised by these results?" "What might users have been thinking?" "What would we do differently knowing this?" Encourage diverse perspectives, especially from team members who interact with users regularly. Document key insights, decisions, and action items immediately. End every session with clear next steps, assigned owners, and deadlines. Without concrete actions, even the best insights fade into good intentions.
Surprises and edge cases often contain more valuable information than expected results. These anomalies challenge your assumptions and reveal opportunities others miss.
When data doesn't match expectations, dig deeper instead of dismissing outliers. That one user who used your product completely differently might represent an underserved market. When Airbnb noticed a small group booking the same apartments Monday through Thursday for months, they discovered business travelers who preferred apartments over hotels. This outlier behavior led to Airbnb for Work, a multi-billion dollar opportunity hidden in just 3% of their bookings. The feature everyone ignored might solve the wrong problem brilliantly. Systematic analysis of anomalies often leads to breakthrough insights.
Create a process for capturing and analyzing surprises. During retrospectives, explicitly ask: "What didn't go as expected?" Document these surprises alongside your main findings. Look for patterns across multiple experiments. Recurring anomalies often signal fundamental misunderstandings about user needs or market dynamics. Transform these surprises into new hypotheses for future testing.
Understanding user mental models transforms confusing behaviors into logical actions. The gap between how you think your product works and how users actually perceive it drives most usability issues. Users approach your product with existing mental models shaped by their experiences. When these models clash with your design, friction occurs. Instead of forcing users to adapt, successful products align with user expectations or gently guide them toward new models. Observe how users describe your product in their own words. These descriptions reveal their mental framework.
Bridge the gap between design intent and user reality through empathy and observation. When users consistently struggle with a feature, the problem likely lies in mismatched mental models, not user incompetence. Study how users currently solve the problem your product addresses. Their existing workflows and terminology provide clues for more intuitive design. Great products feel familiar even when they're revolutionary because they respect how users already think.
Post-experiment decisions determine whether insights drive action or collect dust. Clear frameworks help teams move from learning to implementation confidently. Every experiment leads to one of 3 decisions:
- Iteration means your core hypothesis has merit but needs refinement. Maybe users want the solution but at a different price point, or the feature works but needs better onboarding.
- Pivoting acknowledges your fundamental assumption was wrong. You're not tweaking details but changing direction entirely. Perhaps you discovered users don't have the problem you thought they did, or your solution creates more friction than value.
- Persevering means strong validation that justifies scaling up your investment and moving toward full implementation.
The key is setting decision thresholds before running experiments. Define what validation levels trigger each response. For example: "If less than 20% of users complete the core action, we pivot. Between 20-40%, we iterate. Above 40%, we persevere." Factor in both quantitative metrics and qualitative feedback. Strong numbers with confused users suggest iteration. Weak numbers but passionate user feedback might also warrant iteration rather than abandonment.
Document your reasoning alongside your decision. Future teams need to understand not just what you decided but why. Build checkpoints into your roadmap to revisit these decisions as you gather more data.


Individual experiments create insights. A systematic learning repository creates competitive advantage. Teams that capture and share learnings outperform those that repeatedly rediscover the same truths.
Build a searchable repository of experiment
Transform your repository from a graveyard of documents into a living resource. Schedule regular reviews of past experiments to identify patterns. What assumptions do you repeatedly get wrong? Which user segments consistently surprise you? Create learning summaries that distill insights from multiple experiments. Share these broadly to prevent other teams from repeating mistakes. Your learning vault becomes more valuable over time, compounding the return on every experiment you run.
References
- Product Discovery Basics: Everything You Need to Know | Product Talk
Topics
From Course

Images provided by

Share















