Interaction Design Policies
Master the art of creating effective guardrails and controls for AI-generated content.
AI systems constantly make decisions about what content to generate, often in unpredictable ways. Guardrails act as the safety nets and creative boundaries that keep these systems aligned with human needs. When a chatbot responds to a user, generates an image, or recommends a product, it's the invisible guardrails that determine what's acceptable and what's not. These design policies shape everything from tone of voice to factual accuracy, ensuring AI stays helpful rather than harmful. Content boundaries protect users from potentially offensive material while maintaining brand consistency across thousands of AI-generated interactions.
Style controls allow for personality and context-appropriate responses, whether formal documentation or casual conversation. Behind every natural-feeling AI interaction lies careful design work in factuality verification, determining when to be confident, when to cite sources, and when to admit uncertainty. Even the best AI systems occasionally produce hallucinations or errors, making fallback behavior design critical. Well-designed recovery paths maintain user trust by gracefully handling edge cases rather than delivering confident but incorrect responses.
Organizations developing effective guardrails balance creativity with constraints, allowing AI systems room to be helpful while preventing problematic outputs. As these technologies become more powerful, these interaction design policies become increasingly essential to creating AI experiences that users can genuinely trust and rely on.
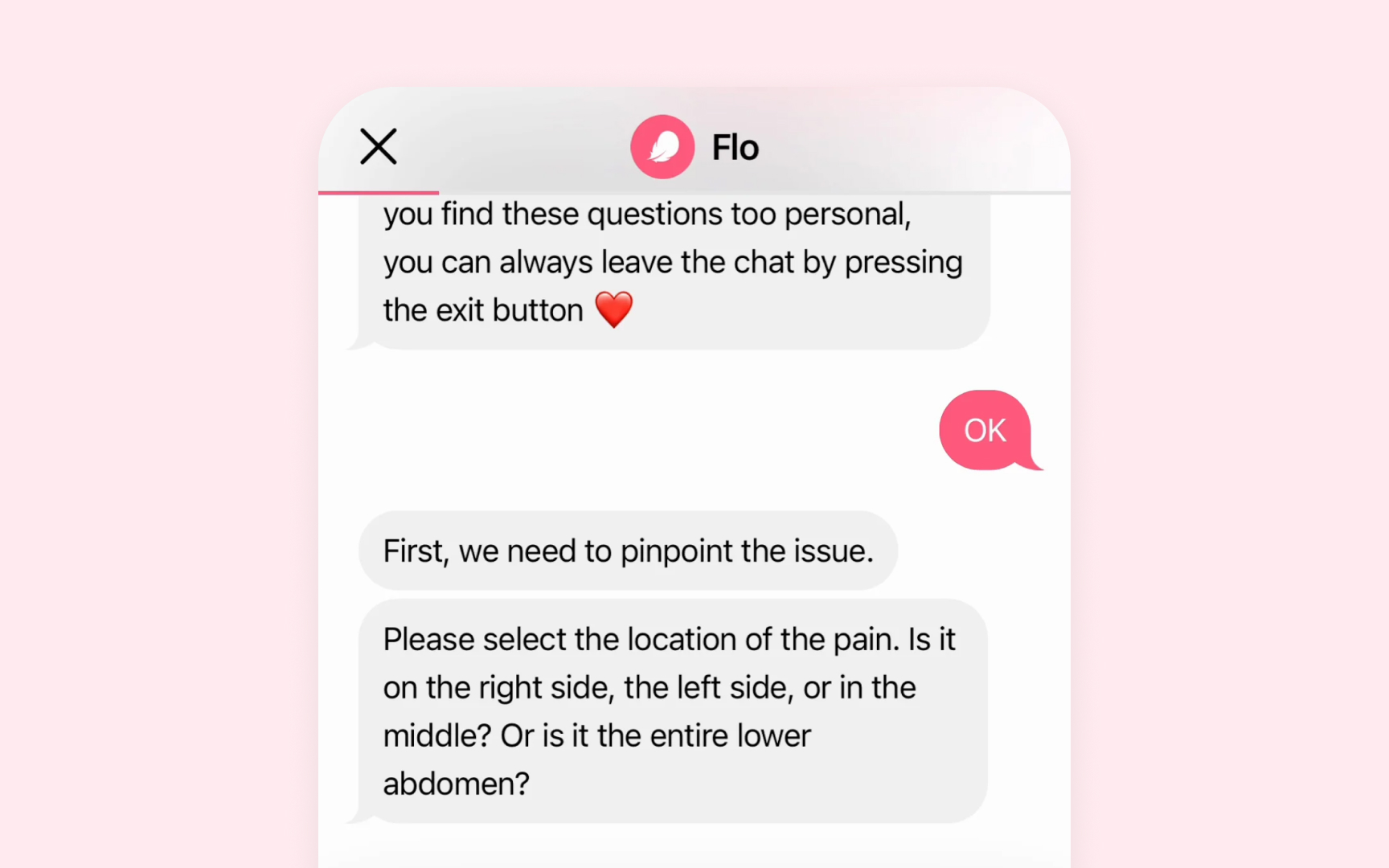
Guardrails in
- Appropriateness guardrails filter out toxic, harmful, biased, or stereotypical
content before it reaches users. - Hallucination guardrails ensure AI-generated content doesn't contain factually wrong or misleading information.
- Regulatory-compliance guardrails validate that content meets general and industry-specific requirements.
- Alignment guardrails ensure that generated content aligns with user expectations and maintains
brand consistency. - Validation guardrails check that content meets specific criteria and can funnel flagged content into correction loops.[1]
The appropriate guardrail implementation depends on context and industry. Financial or healthcare applications typically require stricter guardrails due to regulatory requirements and risk factors, while creative tools might allow more flexibility to support user expression. Effective guardrail design balances AI flexibility with the importance of safe, predictable outputs.
Pro Tip: Map your guardrail requirements on a spectrum from high to low restriction, then adjust based on risk assessment and user testing.
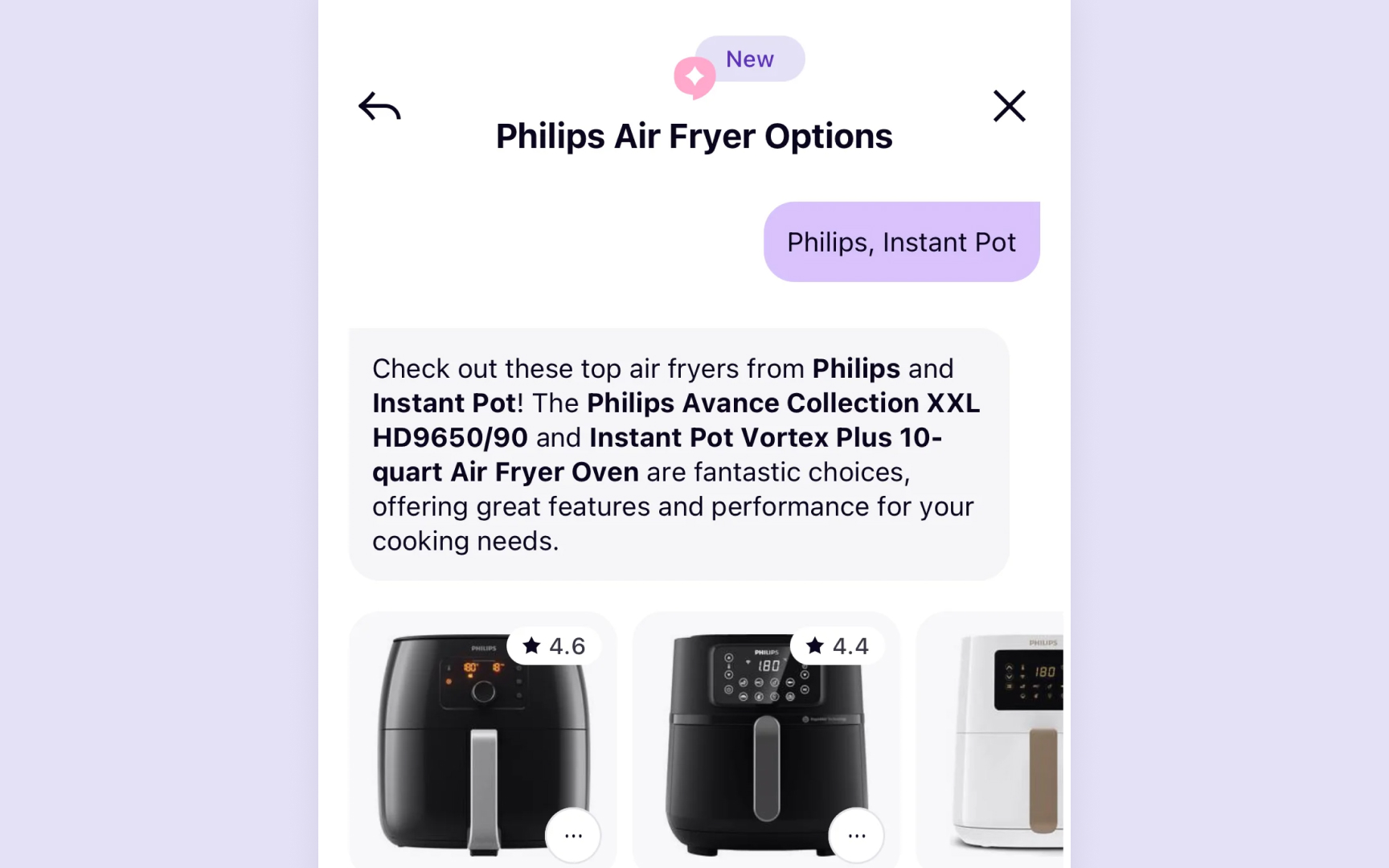
- Protecting users from harmful content
- Maintaining
brand consistency - Meeting regulatory requirements
- Ensuring appropriate experiences for different audiences
When establishing content boundaries, consider both prohibited content, or what the AI should never discuss, and encouraged content, or areas where the AI should excel. Boundaries are implemented through technical measures like prompt engineering, input filtering, output scanning, and human review processes. According to industry experts, boundaries should be regularly reviewed and updated as usage patterns evolve, new edge cases emerge, and societal standards change. Effective content boundaries are transparent to users, helping set expectations about what can be requested while maintaining AI usefulness.
Pro Tip: Create a living document of content boundaries with examples of both acceptable and unacceptable outputs for team alignment.
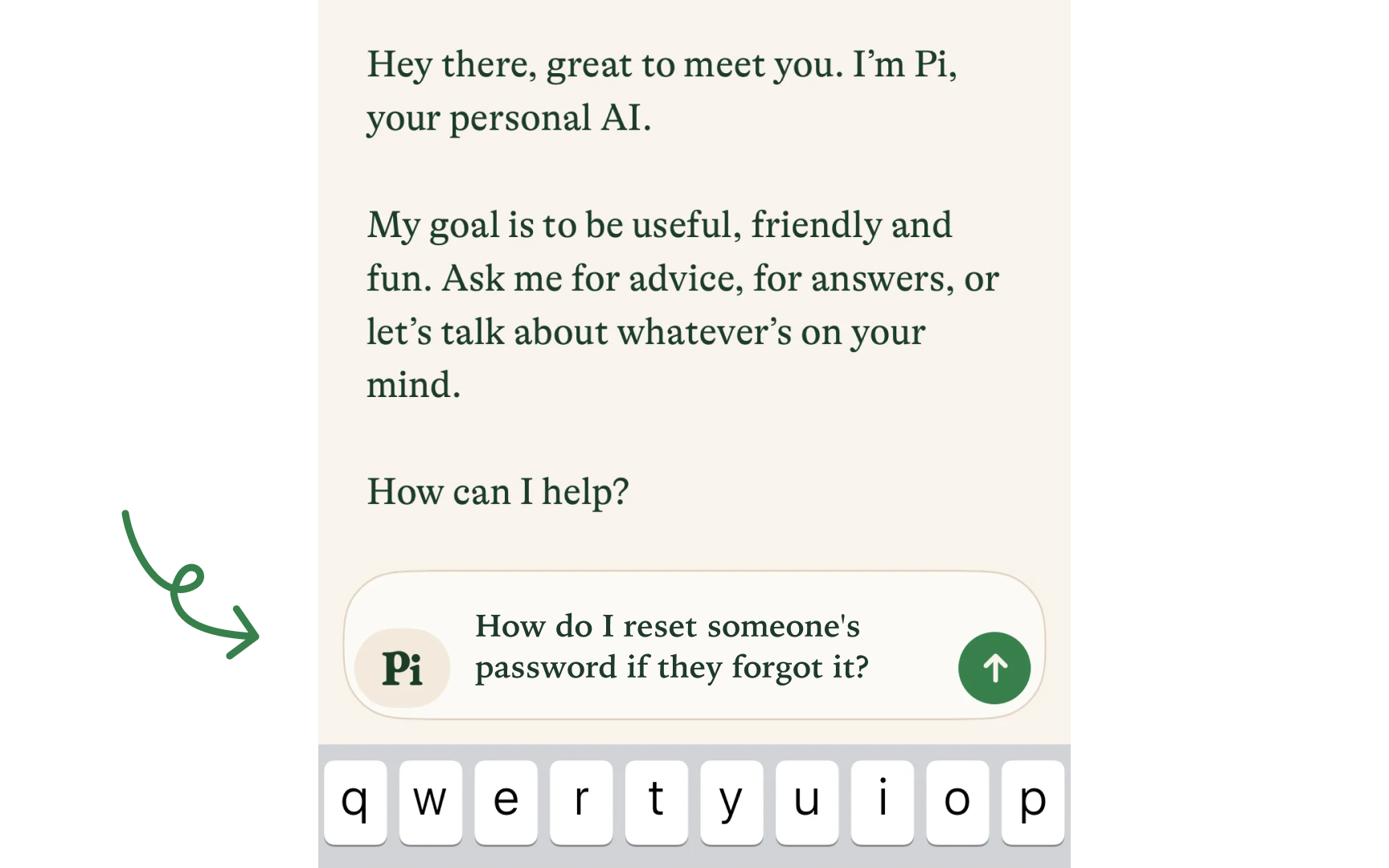
Safety
Safety filters use various technical approaches, including keyword matching, machine learning classifiers, semantic analysis, and pattern recognition.
The technical implementation should be calibrated based on risk levels with stricter settings for public-facing applications or services with vulnerable users. A critical but often overlooked aspect is the user experience when content is filtered, providing clear explanations about why something was blocked and offering constructive alternatives creates transparency without enabling circumvention.
Alignment guardrails ensure that generated
For example, a brand focused on accessibility might prioritize clear, jargon-free language in every
Pro Tip: Collect examples of ideal brand voice from existing content, then use them to guide AI tone calibration.
Alignment guardrails ensure generated
Implementable tone parameters include:
- Formality level
- Technical complexity
- Sentence structure variety
- Use of figurative language
- Emotional resonance
Style controls can modulate conciseness, detail level, use of industry terminology, and examples selected. Advanced systems might adapt tone dynamically based on conversation history or user behavior, gradually matching the user's communication style.
Pro Tip: Create tone personas with sample outputs for different contexts to guide implementation and ensure appropriate tone variations.
Hallucination guardrails ensure AI-generated
Verification can include fact-checking against knowledge bases, requiring sources for claims, confidence scoring, and flagging statements that need verification. Well-designed systems make their confidence visible to users through both words and visual cues, helping people know how much to trust the information.
Hallucination guardrails need citation systems to show where information comes from. Good citation helps users trust
- When citations are needed, usually for specific facts, quotes, or claims.
- What format to use, for example, formal citations or simple links
- How to display them: inline, footnotes, or expandable notes
The best citation systems also give context about how reliable and recent the sources are. For AI systems, it's especially important to clearly show the difference between information from verified sources and
Pro Tip: Show basic source information by default, with options for users to see more details if they want them.
Creating effective hallucination detection requires systematic testing approaches beyond basic accuracy measures:
- Red teaming: Specialized teams deliberately try to provoke hallucinations to uncover edge cases.
- Adversarial testing: Testing with questions in areas of limited
AI knowledge to trigger false information, such as questions about obscure topics. - Benchmark testing: Measuring performance against curated sets of factual and counterfactual statements.
When evaluating these systems, track both false positive rates (legitimate
Validation guardrails check if
- Clear explanations: Tell users why their request couldn't be fulfilled exactly as asked.
- Alternative suggestions: Offer similar but acceptable options instead of just saying "no."
- Refined prompts: Suggest better ways to phrase their request.
- Confidence options: Present multiple possibilities with indicators showing reliability.
- Human escalation: Offer connection to human assistance for complex issues.
Different issues need different recovery approaches. Content with potential factual
Pro Tip: Test recovery paths with real users to ensure they feel helpful rather than frustrating when guardrails are triggered.
Sometimes
When designing human escalation workflows:
- Make it clear when and why escalation is happening
- Set realistic expectations about response timing
- Keep users informed about where they are in the process
- Maintain a consistent tone between AI and human communication
- Use triage systems to prioritize urgent cases
Well-designed escalation presents human support as complementary to AI capabilities, not just a backup for failures. The best systems create a seamless experience where users feel their needs are being met, regardless of whether they're interacting with AI or humans.
References
Top contributors


Topics
From Course

Share
















Similar lessons

AI’s Role in Text Generation and Modification

Best Practices and Potential Pitfalls of AI Writing Tools
