Understanding AI system drift
AI systems can change over time even without explicit updates. The training data your model learned from represents a snapshot of the world at one moment. But the real world keeps evolving, creating mismatches between what your AI learned and what it encounters.
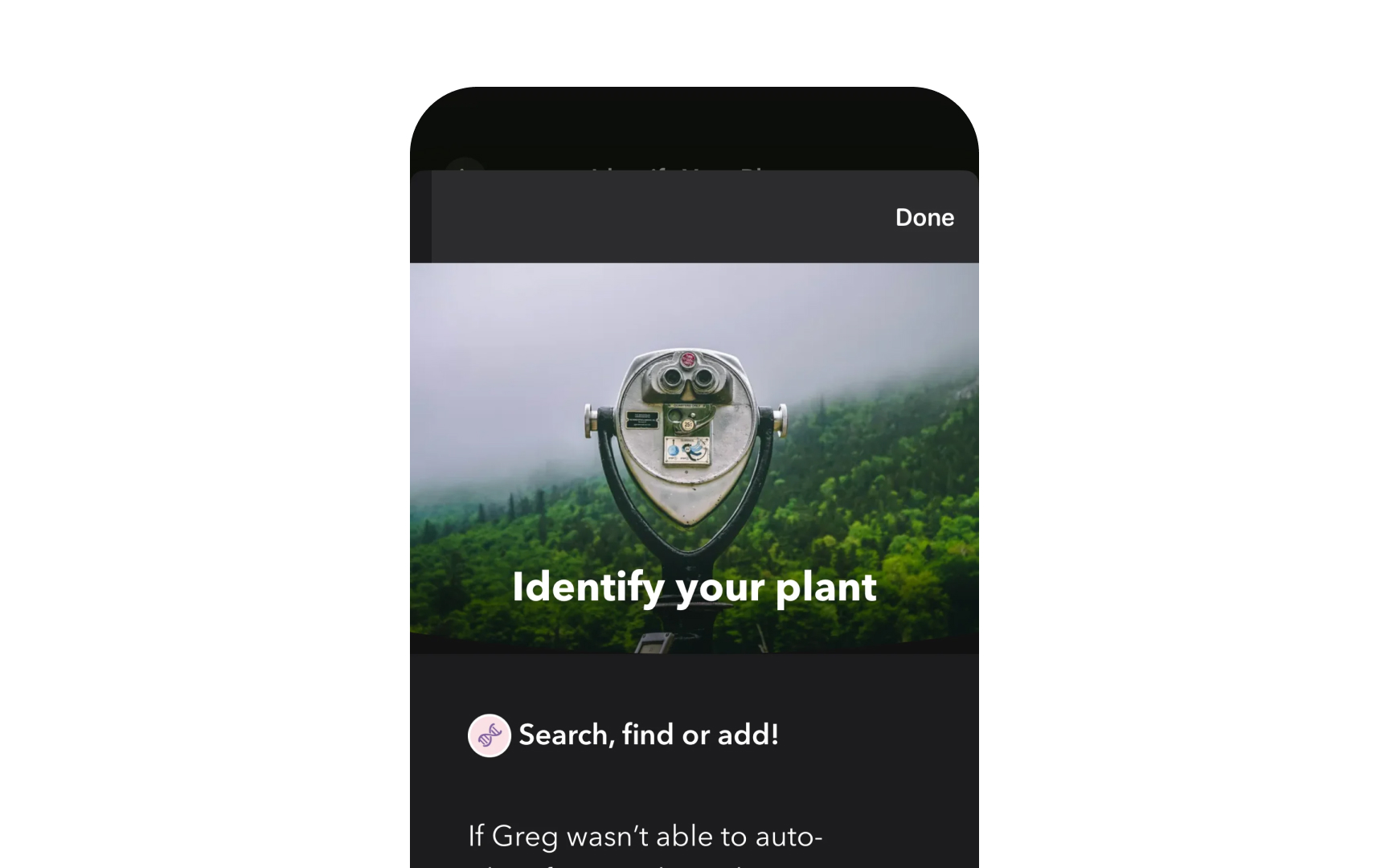
Data cascades occur when initial data decisions create downstream effects throughout the development pipeline. A plant identification app trained mostly on North American species might work well at launch but fail when South American users arrive. The mismatch between training data and real-world usage wasn't visible until users reported errors.
These cascades can be hard to diagnose. You might not see their impact until users experience problems. The effects of poor data choices compound over time, making early planning critical.
Your AI's performance can degrade as the world changes around it. Language patterns shift, user behaviors evolve, and new trends emerge that weren't in your original dataset. Regular monitoring helps detect when reality diverges from your training assumptions. Planning for high-quality data from the start prevents many evolution problems. This means considering how your data might age and building in processes for updates.[1]
