Reinforcement Learning from Human Feedback
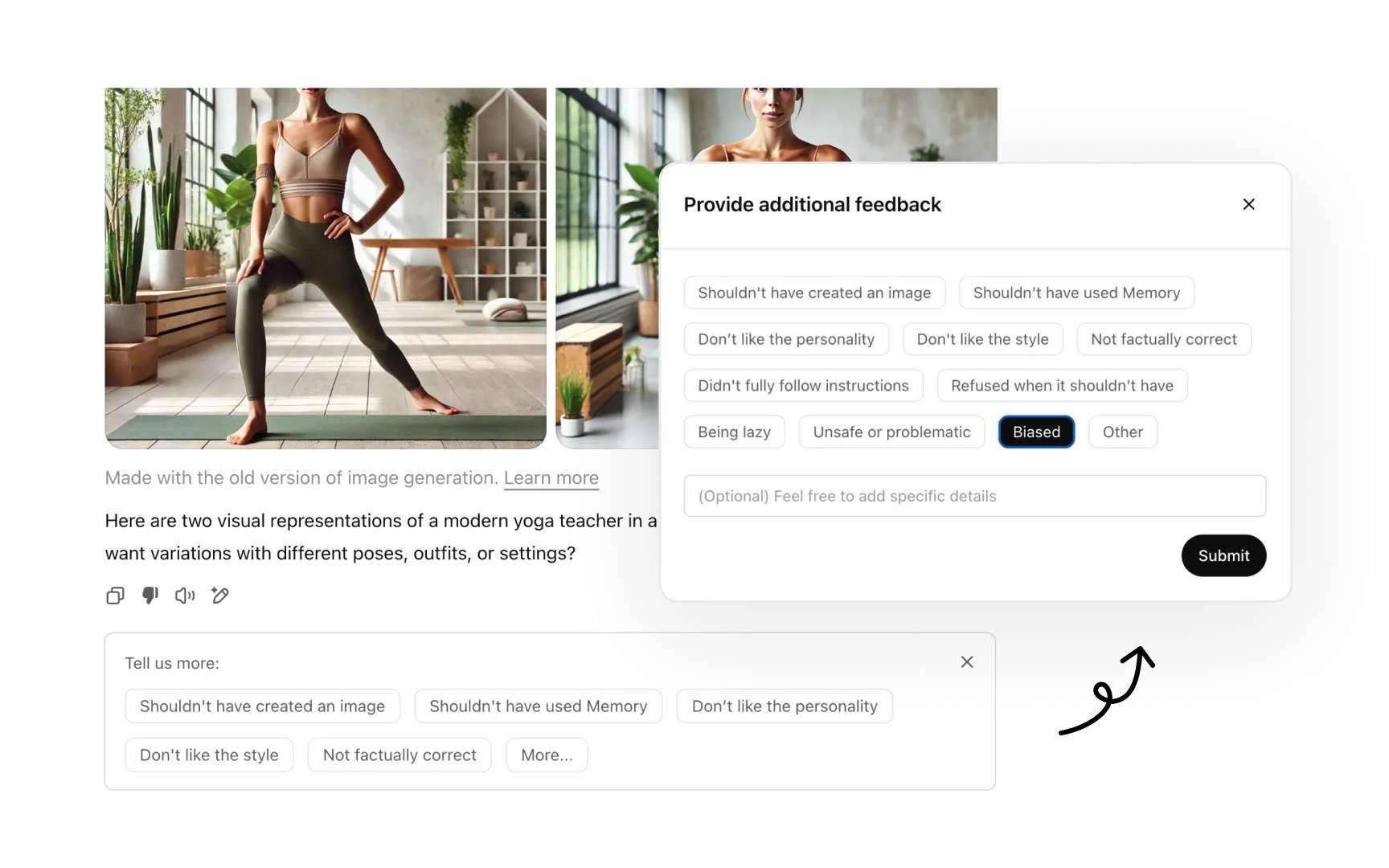
Reinforcement Learning from Human Feedback (RLHF) has become a standard approach for improving AI models like ChatGPT, GPT-4, and other large language models. This process involves collecting user evaluations on AI outputs and using this data in subsequent training cycles to align models with human preferences. While the AI system doesn't learn directly from users’ feedback, these interactions become valuable training signals for developing future versions. The RLHF process typically involves presenting users with opportunities to rate responses, choose between alternative outputs, or categorize why a particular response was unsatisfactory.
This specific categorization provides much more valuable training data than a simple negative rating alone. To maximize the quality of collected feedback, interfaces should clearly explain how user contributions help improve AI technology, motivating people to provide thoughtful responses rather than reflexive ratings.
Top contributors

